로컬 Kubernetes 클러스터(K3s)에서 NVIDIA GPU(RTX 4070 Ti)의 상태를 실시간으로 모니터링하기 위한 풀 스택 구축 과정을 정리합니다.
1. 환경 구성
- OS: Ubuntu 24.04 LTS
- GPU: NVIDIA GeForce RTX 4070 Ti
- K8s: K3s (v1.33.6+k3s1)
- Runtime: containerd (NVIDIA Container Toolkit 설치됨)
2. NVIDIA Device Plugin 설치 및 이슈 해결
Kubernetes가 GPU 자원을 인식하게 하려면 nvidia-device-plugin이 필요합니다.
이슈 발생: CDI 관련 오류
설치 중 unresolvable CDI devices management.nvidia.com/gpu=all 오류와 함께 Pod가 RunContainerError 상태에 빠지는 현상이 발생했습니다. 이는 최신 NVIDIA 컨테이너 툴킷이 CDI를 사용하려 할 때, 관리용 장치 스펙이 누락되어 생기는 문제입니다.
해결 방법: CDI 스펙 보완
호스트에서 아래 명령어를 실행하여 management.nvidia.com/gpu 종류를 수동으로 정의해 주었습니다.
# CDI 스펙 재생성 및 관리용 종류 추가
sudo nvidia-ctk cdi generate --output=/etc/cdi/nvidia.yaml
cat <<EOF | sudo tee /etc/cdi/nvidia-management.yaml
cdiVersion: 0.5.0
kind: management.nvidia.com/gpu
devices:
- name: all
containerEdits:
deviceNodes:
- path: /dev/nvidia0
- path: /dev/nvidiactl
- path: /dev/nvidia-uvm
- name: "0"
containerEdits:
deviceNodes:
- path: /dev/nvidia0
- path: /dev/nvidiactl
- path: /dev/nvidia-uvm
EOF
# K3s가 참조하는 경로로 복사
sudo cp /etc/cdi/*.yaml /var/run/cdi/이후 nvidia-device-plugin을 설치하여 GPU가 Allocatable 자원에 정상적으로 등록되는 것을 확인했습니다.
3. Prometheus & Grafana 설치
가장 널리 쓰이는 kube-prometheus-stack을 Helm으로 설치합니다.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
kubectl create namespace monitoring
helm install prometheus prometheus-community/kube-prometheus-stack -n monitoring4. NVIDIA DCGM Exporter 설치 및 연동
DCGM Exporter는 GPU 온도, 사용률, 메모리 등의 메트릭을 Prometheus 포맷으로 노출합니다.
DCGM의 핵심은 다양한 메트릭과 텔레메트리 데이터를 ‘필드’라는 구조로 구성해 제공하는 것입니다. 각 필드는 고유한 식별자와 번호를 가지며, GPU 온도, 클럭 속도, 사용률, 전력 소모 등 GPU 상태 전반을 나타냅니다. 사용 가능한 전체 필드 목록은 공식 문서에서 확인할 수 있습니다.
일반적으로 다음과 같은 항목들을 포함합니다:
- GPU 사용률 메트릭: GPU가 얼마나 활발히 사용되고 있는지를 측정합니다. 연산 코어 부하, 메모리 사용량, I/O 처리량, 전력 소비 등의 지표를 통해 GPU가 실제 작업을 수행 중인지 유휴 상태인지 파악할 수 있습니다.
- GPU 성능 메트릭: GPU가 얼마나 효율적으로 동작하고 있는지를 나타냅니다. 클럭 속도, 온도 상태, 쓰로틀링 이벤트 등의 지표를 통해 성능과 병목 여부를 평가할 수 있습니다.
helm repo add nvidiamonitoring https://nvidia.github.io/dcgm-exporter/helm-charts
helm repo update
# ServiceMonitor를 활성화하여 Prometheus가 자동으로 수집하도록 설정
helm install dcgm-exporter nvidiamonitoring/dcgm-exporter
-n monitoring
--set serviceMonitor.enabled=true
--set runtimeClassName=nvidia
--set "resources.limits.nvidia\.com/gpu=1"주의사항: Prometheus 라벨 매칭
Prometheus Operator가 DCGM Exporter의 ServiceMonitor를 인식하게 하려면 라벨 작업이 필요합니다.
kubectl label servicemonitor -n monitoring dcgm-exporter release=prometheus --overwrite5. Grafana에서 GPU 대시보드 확인
Grafana 접속
# 비밀번호 확인
kubectl get secret --namespace monitoring prometheus-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
# 포트 포워딩
kubectl port-forward -n monitoring svc/prometheus-grafana 3000:80대시보드 임포트
- 브라우저에서
localhost:3000접속 (ID:admin). - Dashboards -> Import 메뉴 이동.
- NVIDIA 공식 대시보드 ID
15117입력 후 Load. - 데이터 소스를
Prometheus로 선택하고 완성
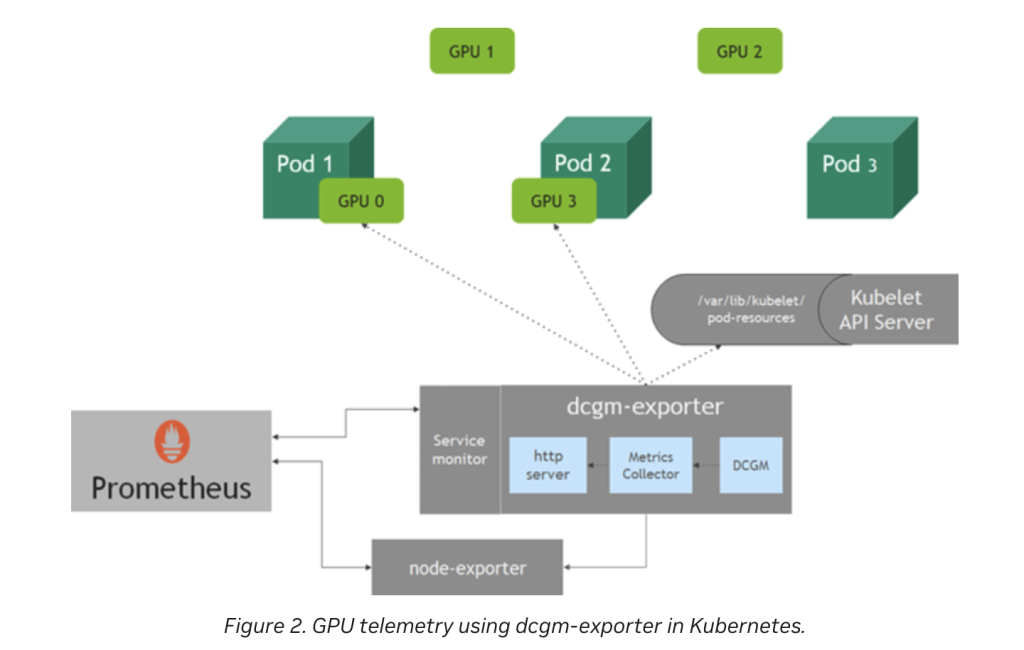
아키텍처
참고> https://developer.nvidia.com/blog/monitoring-gpus-in-kubernetes-with-dcgm/
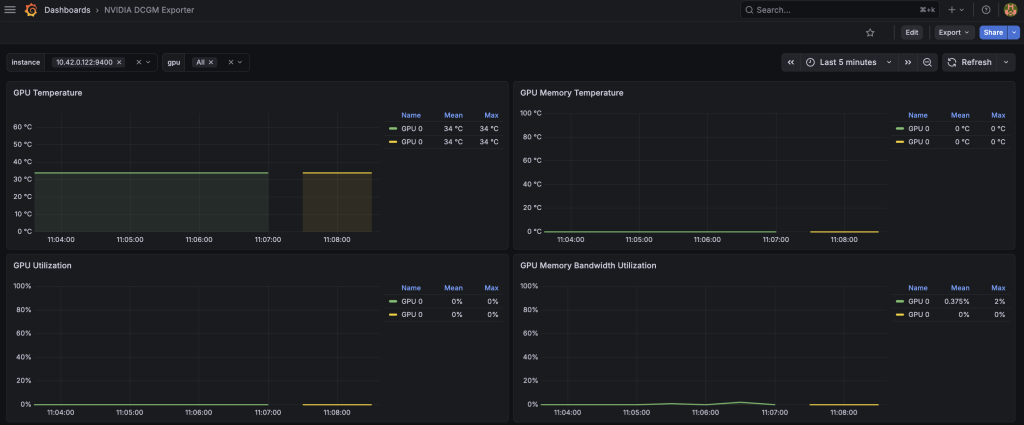


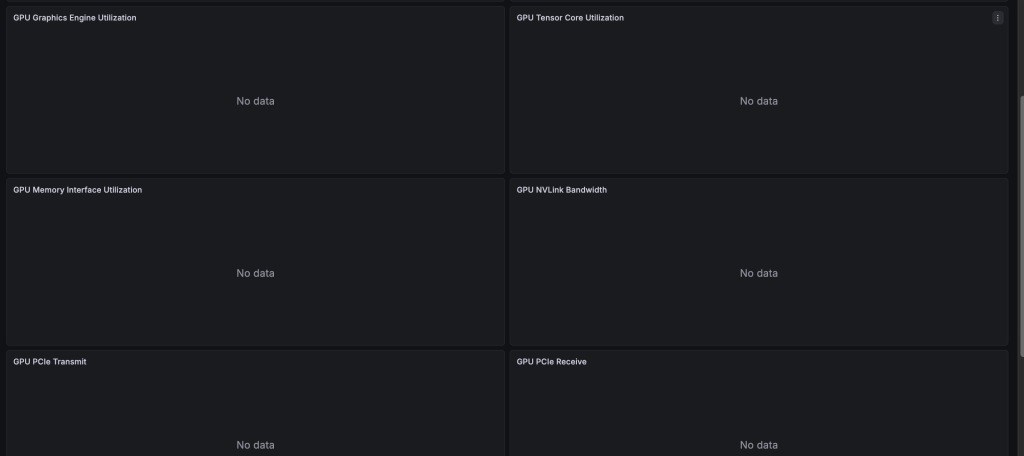
GPU 온도 전력, 메모리 대역폭사용률등은 잘 확인할 수 있으나
몇가지 정보는 나오지 않는데, RTX시리즈여서 100%호환되지 않을 수 있습니다.